

Hierarchical text-conditional image generation with clip latents입니다.
최근 chatGPT로 또 세상을 놀라게 한 openAI에서 만든 dall-e 2에 대한 논문입니다. 본 논문에서는 이 모델을 unCLIP이라는 이름으로 지칭합니다.
Abstract

초록 부분입니다.
먼저 배경부터 설명 드리겠습니다. 본문에서는Contrastive Learning Image Pretraining 즉 CLIP이 representation을 잘 학습해왔다고 평가합니다. (이미지를 feature 벡터에 매핑을 잘 하였다는 의미) 이러한 representations을 이용하여 이미지 생성을 해 보는 것이 이 논문의 배경입니다.
저자는 생성 방법으로 2가지 모델을 이용할 것을 제안합니다. 첫 번째 모델은 prior입니다. 이 모델은 주어진 텍스트를 기반으로 하여 CLIP 이미지 임베딩을 생성합니다. 두 번째 모델은 decoder입니다. Decoder는 prior에서 생성한 CLIP 이미지 임베딩을 기반으로 이미지를 생성하는 모델입니다.
결론으로는 Decoder에서 생성한 이미지는 의미와 스타일을 잘 갖춤과 동시에 다양한 variation을 생성할 수 있음을 예시와 함께 보여줍니다.
Introduction

Introduction 부분입니다. 위 그림은 dall-e 2가 생성한 이미지로서, ‘코기 얼굴 모양의 초신성 폭발’을 텍스트로 제시했을 때 생성된 그림입니다. 그 밖에도 타임 스퀘어에서 스케이트보드를 타는 곰 인형이나, 치즈를 들고 있는 나폴레옹 복장을 한 고양이를 묘사하는 포스터 등, 사전에 존재하지 않는 이미지를 생성하도록 요구하여도 그 조건에 맞추어 그림을 잘 그린다는 것을 보여줍니다.
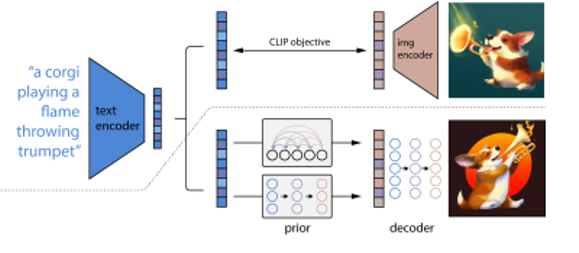
먼저 CLIP과 unCLIP의 구조에 대해 설명드리겠습니다. 그림 중간을 보면 점선이 있는데 위의 부분은 CLIP이고 밑 부분은 unclip입니다. 이 그림은 다음 장에서 자세히 설명 드리겠습니다.
introduction에서는 다시 한번 CLIP이 성공적인 representation learner라고 합니다. 그리고 CLIP을 GAN이랑 비교를 하는데요. GAN은 일일이 검사해도 의도한 결과에서 벗어나는 등 불확정성을 띄지만 CLIP은 단지 encoded된 텍스트 벡터의 direction을 이동함으로써 이미지를 의미적으로 수정을 할 수 있다고 합니다.
그리고 Dall-e 2와 GLIDE를 비교합니다. GLIDE 또한 매우 성공적인 text-to-image 시스템인데요. 그래서 본 논문의 핵심 비교 대상입니다. Dall-e 2와 비교했을 때 quality면에서는, 즉 현실성과 미적인 면에서는 비슷했으나, 다양성에서는 Dall-e 2가 훨씬 뛰어났다고 합니다.
Methods

unCLIP은 2가지 모델, 즉 prior과 decoder 부분으로 구성됩니다. 먼저 prior 모델은 text captions y, 즉 텍스트가 들어갔을 때의 CLIP의 IMAGE embeddings 즉 Zi를 생성합니다. 그리고 그 zi와 text caption y를 조건으로 decoder 모델이 이미지를 생성합니다.
(input으로 들어오는 이미지를 x로, caption을 y로 이 caption의 클립에서의 latent를 zt로 이미지의 clip에서의 latent를 zi로 표현)

Decoder 부분부터 먼저 설명 드리겠습니다. Diffusion 모델이란 데이터에 노이즈를 조금씩 더해가거나 조금씩 복원해가는 과정을 통해 데이터를 생성하는 모델입니다. Decoder 모델은 GLIDE 모델을 수정하여 4개의 추가적인 토큰을 받아들이고, 이를 GLIDE의 텍스트 인코더에 결합하였습니다. 그리고 더 좋은 결과물을 유도하기 위해, CLIP 임베딩을 10% 비율로, 텍스트 캡션을 50%의 비율로 drop하였다고 합니다.
그리고 decoder 부분에서는 이미지의 화질을 향상시키기 위해 2개의 upsampler model들을 사용하였다고 합니다. 이 upsampler model을 학습시키기 위하여 저화질의 이미지를 순차적으로 화질을 향상시키며 학습했다고 말합니다.
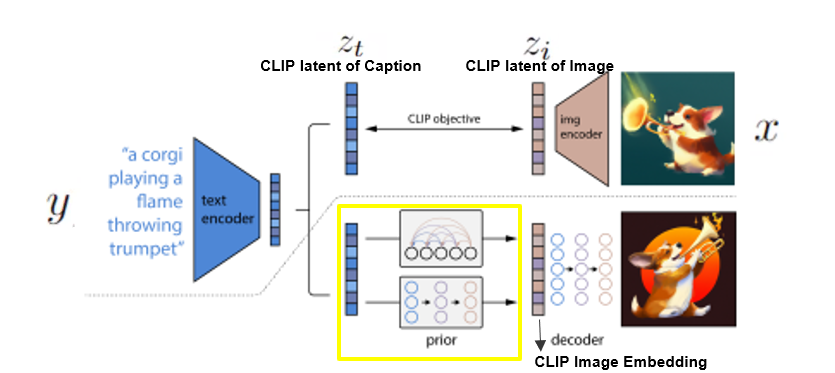
그리고 text embedding을 input으로 받아 image embeddings Zi를 생성하는 prior 모델을 설명드리겠습니다. 이 prior을 위하여 2개의 모델을 사용하여 그 결과물을 비교했다고 합니다. 첫 번째는 Auto regressive prior이고 두 번째는 diffusion prior 입니다.
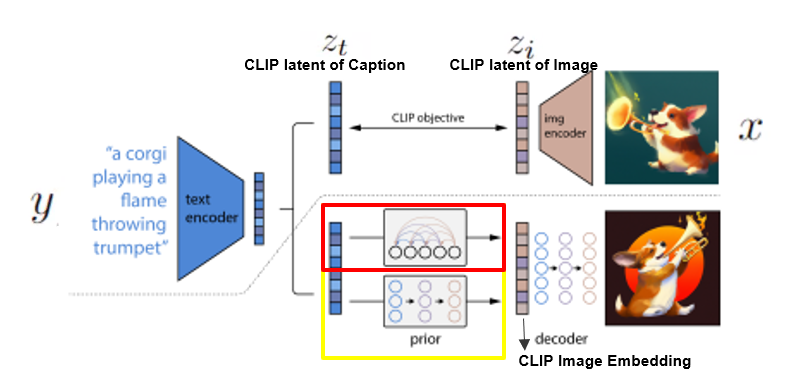
Auto regressive prior에 관하여 먼저 설명드리겠습니다. Auto regressive prior는 clip embedding zi의 차원을 줄이기 위하여 PCA를 사용함으로써, 1024의 차원을 319 차원으로 줄여 계산 복잡도를 줄였습니다.
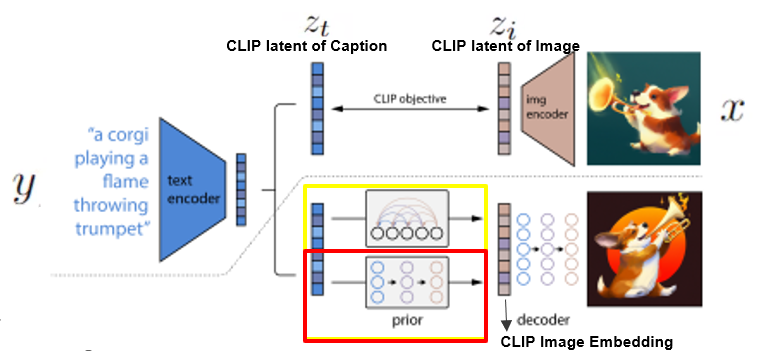
Diffusion prior를 어떻게 학습시켰는지 설명드리겠습니다. Diffusion prior를 위하여 causal attention mask을 활용한 decoder-only transformer를 사용하였다고 합니다. 여기서 transformer란 가장 인기있는 딥러닝 모델로 손꼽히던 CNN과 RNN을 대체하고 있는 모델로, 문장 속 단어와 같은 순차 데이터 내의 관계를 추적함으로써 맥락과 의미를 학습하는 신경망입니다.
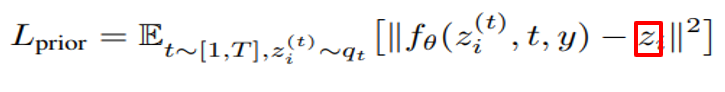
그리고 unnoised zi를 직접적으로 예측하도록 모델을 훈련시켰다고 합니다. 또한, DDPM에서 사용하고 있는 엡실론 prediction formulation이 아닌 mean squared error loss를 사용하였다고 합니다. 여기서 DDPM은 dall-e 2와 비슷하게Diffusion model을 활용한 image generative model입니다.
Mean squared error loss식에서 빨간 네모 부분을 보면 zi가 포함되어 있습니다. Zi를 포함함으로써 직접적으로 zi의 형태가 reconstruct 되도록 prior 모델의 손실함수가 주어지고 있습니다.
Image manipulation
Image manipulation에서는 decoder가 어떻게 이미지를 생성하는지 보여줍니다.

Variation입니다. Dall-e 2에서 이미지 x가 주어졌을 때, 본질적인 맥락을 공유하면서도 다양한 variation을 가지는 이미지를 생성하는 것을 볼 수 있습니다.
왼쪽 그림을 보면 살바도르 달리의 <기억의 지속>이라는 작품을 변형시켰는데, 몽환적인 분위기 와 색감 등을 놓치지 않으면서 다양한 이미지를 생성한 것을 볼 수 있고, 오른쪽 그림에서는 openAI의 로고의 특성을 놓치지 않으면서 다양한 그림을 생성한 것을 볼 수 있습니다.

Interpolations 파트입니다. 위 그림에서 두가지 이미지가 주어졌을 때, interpolation 하는 과정을 볼 수 있습니다.

Text diff 파트입니다. 이 부분은 새로운 텍스트가 주어졌을 때, 그 텍스트의 clip text embedding을 추출하여 원래 이미지의 clip text embedding과 새로운 clip text embedding 간의 interpolation을 통하여 새로운 clip representation을 생성하여 이미지를 생성합니다.
(논문에서도 짧게 넘어가는 부분인데, 만약 텍스트가 없는 이미지의 경우에는 ‘a photo’라는 캡션을 주었다고 합니다. 그럼에도 매우 잘 작동하였다고 합니다.)
그림을 참고하시면 고양이 이미지가 애니메이션 스타일의 초사이언 고양이로 변해가는 과정을 확인할 수 있습니다. 그 밖에도 중세 시대의 집이 현대 시대의 집으로 변해가는 모습, 사자가 아기사자로 변해가는 모습, 겨울이 가을로 변해가는 모습을 볼 수 있습니다.
diff는 difference를 의미합니다.
Probing the CLIP Latent Space
Probing the CLIP Latent Space 입니다. Clip latent space가 어떤 space인지를 자세히 탐구해보는 파트입니다.

CLIP은 언어와 이미지를 둘 다 다루고 있는 Multi-Modal Pre Training Model입니다. 이러한 CLIP은 typographic attack이 가능하다고 합니다. 가장 왼쪽 그림을 참고해 보시면, CLIP으로 Embedding을 하였을 때 사과 이미지는 사과로 100% 인식을 하는데, 사과에 iPod이라는 글자를 적은 그림을 보면 사과를 아이팟 모양으로 변형시킬 수 있는 것이 가능하다는 것을 알 수 있습니다
그림을 자세히 보시면 사과가 아이팟 모양의 사과가 되기도 하고, 아이팟 뒷면 같은 이미지가 생성되기도 하는 것을 볼 수 있습니다. 물론 피자와 사과를 이용한 오른쪽 그림에서는 피자를 잘 생성하지 못하는 것을 볼 수 있는데, 이는 같은 음식 범주 내에서는 typographic attack이 효과적이지 않기 때문입니다.
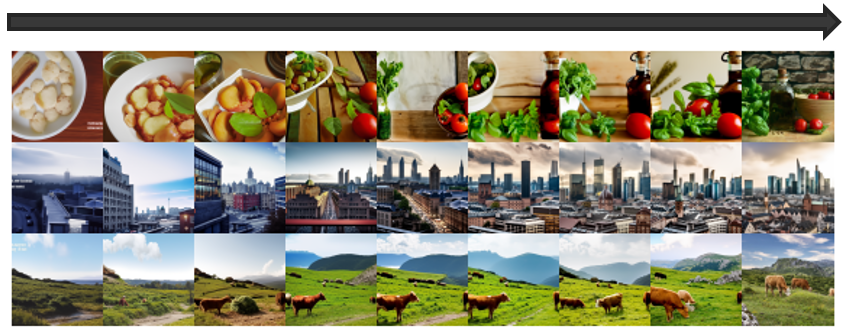
메소드 부분에서 auto regressive prior 부분에서는 PCA를 이용하여 시간 복잡도를 줄였다는 이야기를 하였습니다. 이 부분은 dimension의 개수를 20개로 축소했을 때부터 320개까지 축소했을 때를 비교하려고 합니다. 20개까지 축소 했을 때는 이미지의 컨셉 정도만 이해한 모습을 보이지만, 개수가 늘어남에 따라 이미지를 자세한 부분까지 생성하는 것을 볼 수 있습니다.
Text to image generation

이번 슬라이드는 Prior의 중요성을 언급하는 부분입니다. 각 그림에 선행하는 텍스트가 가장 밑에 쓰여 있습니다. 예를 들어 세 번째 열은 계산기를 사용하는 고슴도치를 caption으로 주었을 때의 그림입니다. 첫 번째 행의 그림은 caption 및 CLIP text embedding을 주지 않았을 때의 그림입니다. 세 번째 열 맨 위의 그림을 보게 되면 고슴도치만을 그린 모습을 보입니다. 두 번째 행은 CLIP text embedding을 컨디션으로 준 그림입니다. 두 번째 그림에서는 고슴도치와 계산기를 그리는 데 까지는 성공하였지만, 고슴도치가 계산기를 사용하지 않는 모습이 보입니다. 그리고 마지막 행은 AR prior model로 caption을 주었을 때의 모습입니다. 마지막 그림에서는 caption의 조건대로 고슴도치가 계산기를 사용하는 모습이 나타납니다.
이 그림을 참고하였을 때, 왜 prior이 중요한 지 알 수 있습니다.
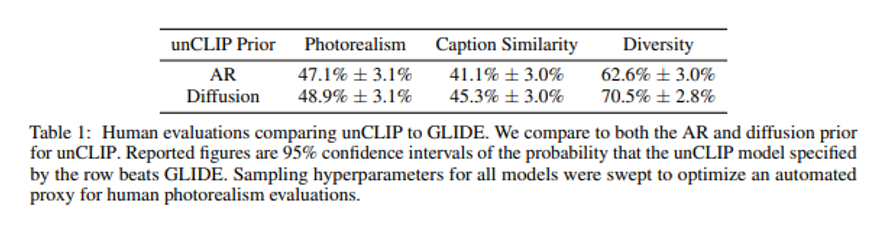
다음 도표는 GLIDE와 비교했을 때, 각 부분에 따른 Dall-e 2 모델의 선호도를 조사한 것입니다. 현실성과 재현성 면에서는 비슷했으나, 다양성에서 unCLIP이 GLIDE보다 선호된다는 것을 알 수 있습니다
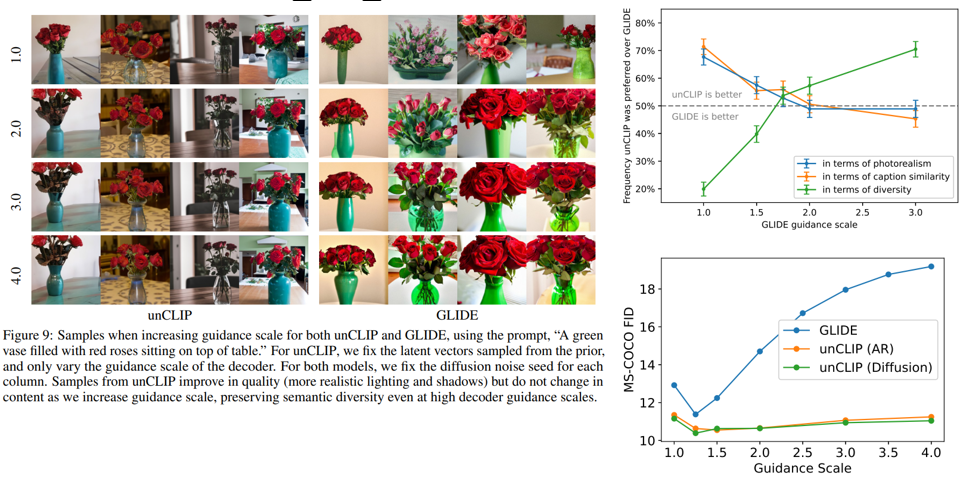
왼쪽 그림을 보실 때 unclip은 guidance scale이 커지더라도 그림의 변화가 미묘하지만, glide에서는 이미지가 점점 다가오는 등, 퀄리티가 낮아지는 것을 볼 수 있습니다.
오른쪽 위 그림은 평가된 내용을 그래프로 나타낸 것입니다. 현실성과 재현성 부분 에서 GLIDE와 unCLIP이 비슷하지만 다양성에서는 unCLIP이 훨씬 낫다는 것을 보여 줍니다.
오른쪽 아래 그래프는 Guidance에 따른 FID를 나타낸 그림입니다. y축인 FID는 높을수록 안 좋은 수치입니다. 오른쪽 표를 보시면 GLIDE는 Guidance Scale이 높아질수록 FID가 높아진다는 것을 볼 수 있습니다.

텍스트 조건부 이미지 생성 모델은 MS-COCO 검증 세트에서 FID를 평가하는 것이 표준 관행이라고 합니다. 여기서 다른 여타 모델과 마찬가지로 unCLIP이 현실적인 장면을 잘 생성하는 것을 알 수 있습니다.
Limitation

그렇지만 한계점이 있습니다. 파란 큐브 위의 빨간 큐브를 caption으로 입력하였을 때, 오히려 GLIDE 에서 훨씬 더 잘 그리는 모습이 보여집니다. unCLIP에서는 색깔이 섞인 큐브를 그리거나, 한쪽 면만 파랗게 그리거나 하는 등, caption과는 거리가 있는 그림을 그립니다.
논문에서는 다음과 같이 비슷한 오브젝트가 2가지 이상이 있고 각 속성이 다를 때에는 GLIDE가 unCLIP보다 좋은 성능을 보여 주었다고 합니다.

또한, caption을 기반으로 한 그림을 재생성하는 부분에서도 문제점이 드러납니다. 재생성한 결과물은 파란 큐브와 빨간 큐브의 순서가 바뀌거나 강아지가 쓴 모자와 넥타이의 색깔이 뒤바뀌는 등, caption에서 명시한 오브젝트의 속성이 뒤섞여서 표현됩니다. 오른쪽 그림에서는 쿠키와 우유가 든 컵의 각 크기를 명확히 그려내지 못하는 모습을 볼 수 있습니다.

그리고 unCLIP의 경우에는 다양성을 지향하는 모델이다 보니, ‘딥 러닝이라고 쓰여진 간판’을 입력했을 때, 중점이 되는 ‘딥 러닝’이라는 낱말 또한 변화시켜 정확한 스펠링을 쓰지 못하는 한계가 있습니다.

다음 예시는 복잡한 장면을 그려내는 부분에서 빌딩의 간판이나 색상 등의 세밀한 표현이 부족함을 나타냅니다.
아래 부분은 저의 의견부분입니다.
Conclusion
저자는 GLIDE에서 다양한 이미지를 잘 생성하지 못하였기에 Dall-e 2, 즉 unCLIP 방식을 개발하였고, 주요 기법으로서 prior과 decoder 모델을 제안 하였습니다.
이미지를 생성하는 decoder가 중요하긴 하지만, prior 또한 text caption을 잘 이해하기 위해서 꼭 필요하다는 것도 언급하였습니다.
본 방식에서는 한계점이 존재하나, 다양성 면에서는 GLIDE를 확실하게 능가하였다고 평가됩니다.
저자는 Dall-E 2를 통해 생성된 결과물은GLIDE와 비슷한 퀄리티를 보이고, 1세대 모델인 Dall-E 대비 훨씬 뛰어난 다양성을 보였다(‘our samples are comparable in quality to GLIDE, but with greater diversity in our generations’)라는 말로 Dall-E 2의 성능을 평가합니다.
General review
논문의 유익한 점: DALL-E 2가 생성한 많은 이미지를 보며 같이 설명해 주어서 논문 리뷰 준비가 쉬웠습니다. 또한, GLIDE와의 구조적 차이 등을 이해하며, 논문에서 다루는 unCLIP 방식 외의 다양한 방식에 대한 배경 지식을 공부할 수 있었습니다.
논문의 아쉬운 점: 다양한 방법을 제시하여 성능이 좋아졌다고 말하였지만, 그 이유와 원리에 대한 자세한 설명이 없는 것이 아쉬웠습니다. 예를 들어 Prior에 diffusion prior의 손실함수인 rmse에서 Zi를 direct하게 학습하였다고 하였는데 그 이유에 대해서는 나와있지 않는 것이 아쉬웠습니다.
그리고 논문에서 중요하게 다루어지는 CLIP에 대한 설명이 없는 것이 아쉬웠습니다. 본문에서는 CLIP에 대한 배경 지식을 수반하여 unCLIP을 설명하는데, 이를 이해하기 위해서는 Learning Transferable Visual Models From Natural Language Supervision논문을 참조하였습니다.